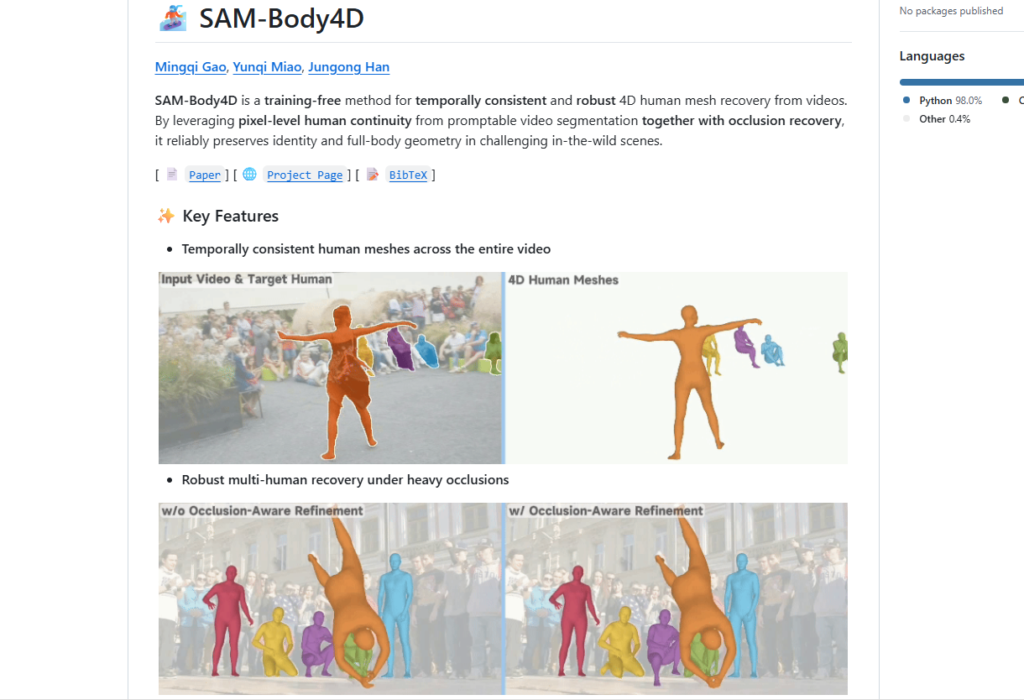
Metaが発表した画像から3Dモデルを生成できるAI「SAM 3D」の動画版、SAM-Body4Dが公開されていたので試してみました。
GitHubではブレイクダンスの分析例もあります。
Google Colab Proで実行
Google Colabではムリで、Pro契約が必要です。
L4 ハイメモリでも足りない…
普通に動かすと22.5GB GPUでも足りませんでした。
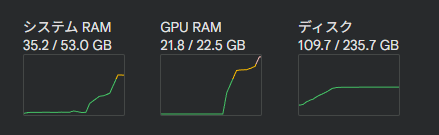
処理をリファクタリングしたらなんとかなるかと思ったのですが、Diffusion-VAS単体だけでVRAMを22GB以上持って行くのでお話になりませんでした。
A100 GPU・ハイメモリであれば余裕で処理できました。
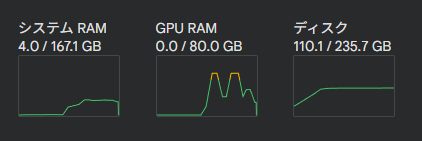
処理が重い原因ですが、被写体が隠れたときにDiffusion-VASを使って姿を生成しているところが怪しそうです。
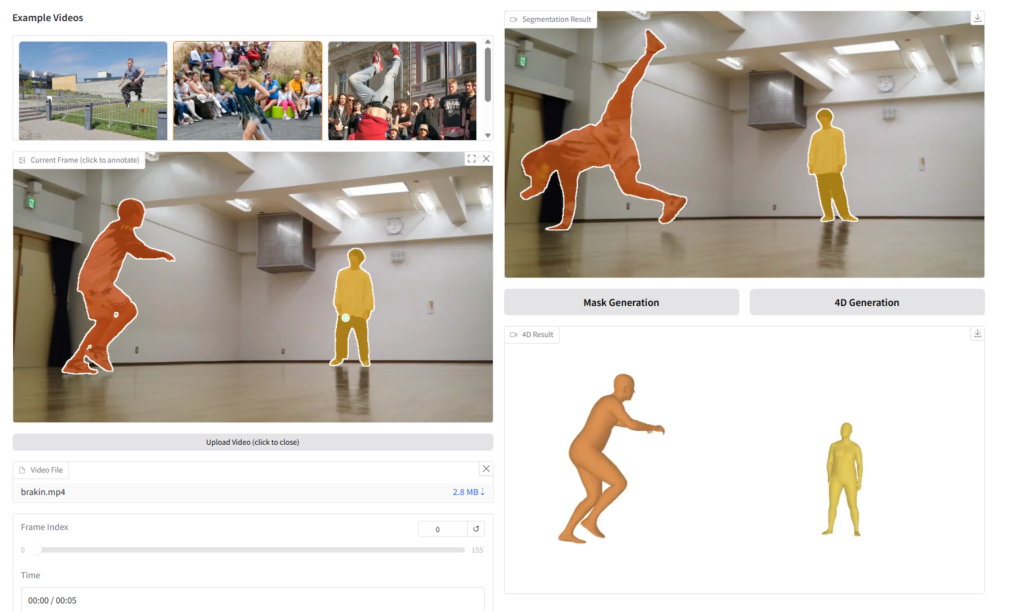
例えば今回分析した動画においては以下のように2名の身体が重なり、奥側のダンサーさんの身体の大部分が隠れてしまったフレームなどもあります。
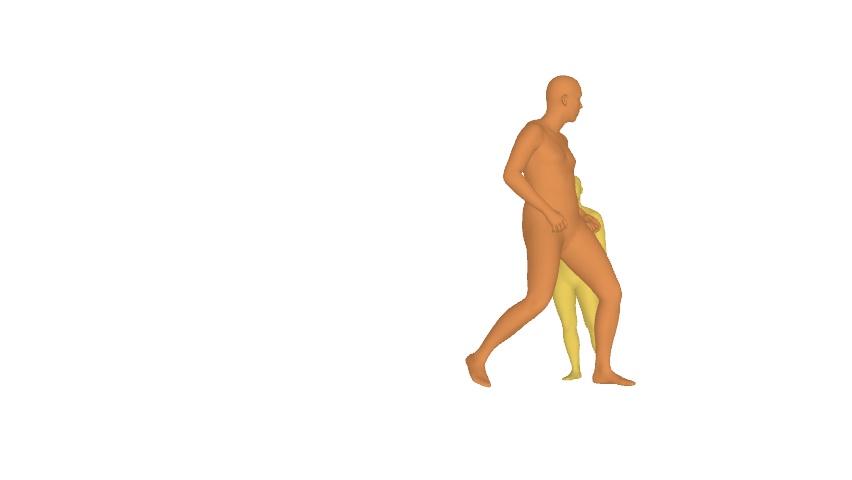
しかしDiffusion-VASによって、以下のような個別の姿が生成されます。
画像生成をしているのであれば、処理が重くて当然… (のはず)


おわりに
SAM 3D Bodyの動画版ぐらいに思っていたのですが、身体が隠れてしまったフレームがあるような場合でも生成AIを利用して連続したモーションを抽出できるようになっていました。
被写体のIDを保持し、カメラから隠れた部分の姿勢を推定するのに、AIで画像生成するというアプローチは面白いですね。
今回はA100GPU・ハイメモリを用いましたが、
実際のところ、ユースケース・シチュエーションに応じてDiffusion-VASまわりを省いてしまうというのもアリだとは思います。
特に身体が隠れるシーンがない、というような動画であれば不要なはずです。(ある程度 SAM 3D Bodyに任せていいはず…)
オクルージョンの処理を除外する
configs/body4d.yaml ファイルの以下の記載を false に変えればよさそうな気がします。
completion:
enable: trueバッチサイズを変更する
また、SAM 3D body でバッチサイズが大きいということがあるので、これを減らすことも効果がありそうです。
( Github の issue に上がっていました https://github.com/gaomingqi/sam-body4d/issues/1 )
sam_3d_body:
# download (ckpt_path & mhr_path): https://huggingface.co/facebook/sam-3d-body-dinov3
ckpt_path: ${paths.ckpt_root}/sam-3d-body-dinov3/model.ckpt
mhr_path: ${paths.ckpt_root}/sam-3d-body-dinov3/assets/mhr_model.pt
# download (fov_path): https://huggingface.co/Ruicheng/moge-2-vitl-normal
fov_path: ${paths.ckpt_root}/moge-2-vitl-normal/model.pt
batch_size: 64







