放送業界の現場では生放送や屋外撮影においてタブーな言葉、いわゆる放送禁止用語が飛び出すケースが少なくなく、従来はピー音などで誤魔化したりディレイを利用してカットするなどの対応がされていました。
最近は音声の生成AIの技術も発展しており、①画像の補完(インペインティング)と同様に音声を補完する『オーディオ・インペインティング “Audio Inpainting”』、②部分修正ではなくフルで生成する『テキスト トゥ スピーチ “TTS: Text-to-Speech”』という2つの分野で研究と実装が進められています。
このような音声を生成するAIが一般的になれば、ワークフローが大きく変わるかも知れません。(そもそも、短尺~長尺の動画自体が生成出来てしまえば撮影自体が不要ですが、業界としてそれを望んでるようには見えていないのですが)
いくつかサービスやOSSを調べてみました。
Audio Inpainting(補完・部分編集)
元データとなる参照音声を読み込み、特定のワードやタイミングを指定して自然な音声を生成し、差し替えたり補完します。
フル生成と異なる点としては、発声したワードが間違っているだけであれば厳密なリップシンクが不要になるということがあります。例えば「荻原(オギワラ)」さんと「萩原(ハギワラ)」さんを間違えた場合など、音声としては全く異なりますが文字数は同じなのでオをハに変更しても元映像の口パクと大きな違和感は無いはずです。
オープンソース:PlayDiffusion
https://github.com/playht/PlayDiffusion
特定ワード置き換えに強いらしいです。GitHub上にサンプルがあるので、確認可能です。
カリフォルニアにある(らしい)会社が提供しているOSSなので、お試し版という感じでしょうか。OSSのライセンスはApache-2.0 licenseなので、商用利用も可能ではあります。
※もし使われる場合は最新情報をご自身でご確認ください。
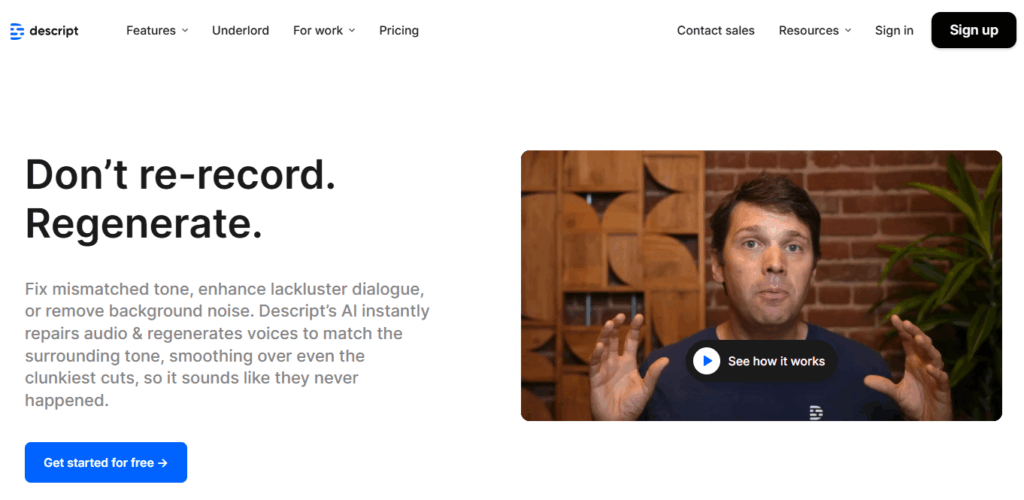
商用:descript “Regenerate”
https://www.descript.com/regenerate
ポッドキャストなどラジオ的な音声コンテンツに対して、撮り直しの代わりに生成AIで差し替えるようなツールです
クリエイター向けには月額$24とのことなので、無料版を試してから課金しても良いかも知れませんね。
商用、音楽向け:Udio
楽曲を作れるサービスで歌の特定の部分だけ差し替える事ができるようです。
このサイトで作成した歌だけでなく、アップロードした楽曲についても編集可能だそうです…。
いくつか部分的な差し替え向けのAIを探しては見たのですが、やはりフル生成の方が活況なようです。
TTS: Text-to-Speech (フル生成)
Chatterbox
https://github.com/resemble-ai/chatterbox
米国シアトルの音声専門AIテック企業のResemble AIが開発し公開しているOSSです。ゼロショット、つまりモデルの追加トレーニングなしでも高い品質で音声を生成できることが強みのようです。
音声のクローニングおよび、フェイク検知の技術を有しており、アメリカのメディア企業に対してサービス提供をしています。
商用版だと低遅延での処理、大規模運用を前提としたスケーリングなどの最適化が行われるようです。クリエイター向けとしてはOSS版で十分かも知れませんね。また改めて試そうと思います。
VoxCPM
https://github.com/OpenBMB/VoxCPM
中国におけるニコニコ動画みたいなサイト「ビリビリ動画」のBilibiliによるOSSです。
そのため現時点では中国語と英語のみサポートしている?ようです。
Huggingfaceにてデモが動かせるようになっています。

https://huggingface.co/spaces/openbmb/VoxCPM-Demo
すでにスタートアップとしては閉鎖済み?coqui-ai TTS
LinkedInの記事「Coqui is shutting down」を見る限り、すでにCoquiというスタートアップ自体は2024年にクローズ。このOSSが残されているような状態のようです。メンテナンスはコミュニティによるものなので、今後どうなるか。
https://github.com/coqui-ai/TTS
元を辿るとFirefoxでおなじみのMozillaによるプロジェクトだったようです。投資家から見て投資の余地が大いにある新しいスタートアップなどの方が資金調達しやすい・成長しやすいなどあったのかも知れませんね。
Zonos

米国カリフォルニアのAI企業のZyphraによるOSSです。
日本語対応もされています。研究要素もあるのか、OSS活動も活発です。
ただ、issueの数がかなりあるので、期待に対してリソースが足りてないのかも知れませんね。
OSSでも商用に負けないレベルの品質があるらしいので、また改めて評価してみたいと思います。ChatterboxとZonosが気になっています。








