
LLMの発展に伴い、口語的な指示でのソフトウェア操作、バーチャルキャラクターやロボットの操作が別次元になりつつあります。Amazon AlexaやApple Siriに命令するような形でAIに指示をすると、それに必要なスクリプトなどが自動で生成、実行されるものです。
いくつか事例と実装テクノロジーをご紹介します。
日本語でのテキトーな指示でバーチャルキャラクター操作
Microsoft社のWebXR向けライブラリである Babylon.js、4~5年前に取り上げたときはv4系だったのも昔で、今はv8.0までバージョンアップされています。高品質で多様な3D表現が可能となっています。
コネチカット大学の方がBabylon.jsを用いた興味深いプロジェクトを公開していました。
https://github.com/AmyangXYZ/PoPo
(なぜかちょっとセクシーな3Dモデルを使っており、会社のオフィスなどでアクセスするのはよろしく無いかも知れません)
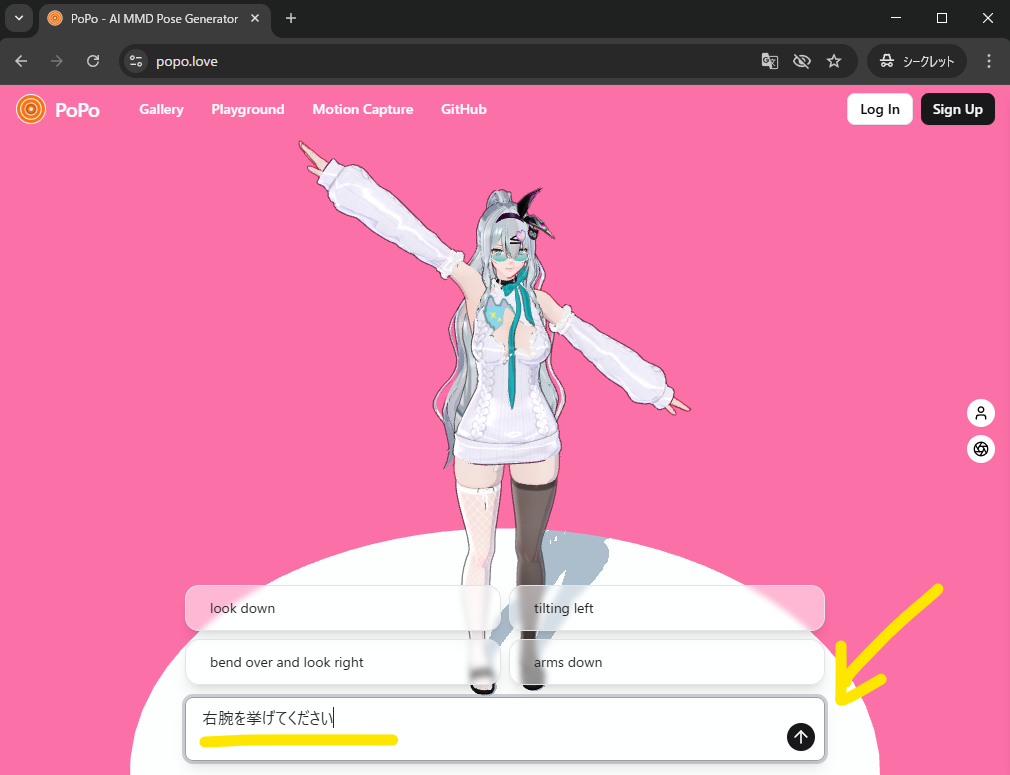
このデモサイトでは、口語的な指示を入力することでバーチャルキャラクターを動かすことができます。
もちろん特定のコマンドで操作するレベルは昔からあるのですが、
最近のAIを使えば上の画像の通り「日本語でのテキトーな指示」も理解することができます。
特定ルール・制限のある空間内であれば、より複雑な指示も実現するようなアプリを作ることも可能かと思われます。
例えばですが「青いブロックを持ち上げろ」と指示すれば、AIがバーチャル空間内にある青いブロックを特定し、そこにキャラクターを移動、持ち上げるアクションを実現する…というようなこともできるかと思います。
そうなってくると、現実でロボットに同様のことをさせるのもできるはず…ですよね。
コンテンツ検索はAIが【 O’Reilly(オライリー)】
エンジニアの方々にとっては「どうせO’Reillyを買うんだから最初からO’Reillyを買え」でおなじみのオライリー書籍ですが、Microsoftと組んでオンライン学習サービスにおける検索機構を提供しているようです。
いわゆるコンテンツはタイトルや詳細情報、メタデータなど、付属している多様な情報から検索する必要があります。だからこそ、意味を理解した上でコンテンツを探せるAIが価値を発揮する…ような気がしますね。
特にフィーリングで視聴作品を選びたいというような動画サイトなどでは、このようなプロンプトベースの検索などが効きそうな気がします。
自分の状態や好みなどを伝えると、いい感じに映画などを紹介してもらえたら面白いですね。ほかにも男性のオタノシミの…
会話型インターフェースを実現するリソース
フロントエンドのガワとして使えるものや、バックエンドとして充実しているサービスがあります。
Microsoft : NLWeb(Natural Language Web)
マイクロソフトが開発しているオープンプロジェクトです。
ユーザーが選択したモデルと独自のデータを組み合わせ、Webサイト向けの自然言語的なインターフェースを簡単に作成できるようにするものです。

Open-VLA
Google Deepmind などが開発しているロボット操作向けのOSSで、カメラで撮影した画像を解析しながらの操作が可能です。上述のバーチャルキャラクター操作ではバーチャル空間の話でしたが、カメラからのインプットを利用することで物理空間での同様の実行を可能にしているわけですね。
VLAはVision, Language, Actionの頭文字のようです。

Cloudflare : AutoRAG
AI時代のバックエンドとして、CDNやDNSなどネットワーク領域で有名なCloudflareに注目しています。

Cloudflareは R2というS3互換のオブジェクトストレージ、Vectorizeというベクトルデータベースも提供しています。
ストレージにデータを雑多に置いて、ベクトル化してデータベースにインデックスを保存、それをAutoRAGに繋げばAI検索システムの出来上がり…となる気がしています。すごい雰囲気があるのは、このデータが非構造化データでもいけそうということでしょうか。
画像や動画、音声、多様なフォーマットのデータを投げ込んで、それらをまとめてAIが管理可能になる…というイメージなのですが、コチラはまた改めてご紹介したいと思います。
つづく








